Восстановление линейной функции нейронной сетью¶
Нейронная сеть: теория¶
В прошлом туториале речь шла об упрощённом нейроне (с одним входом и без активации), который хорошо подходил для восстановления линейной функции. В этом туториале мы усложним архитектуру нашей модели и составим уже сеть из нейронов с одним скрытым слоем (количество выходов оставим равным единице):
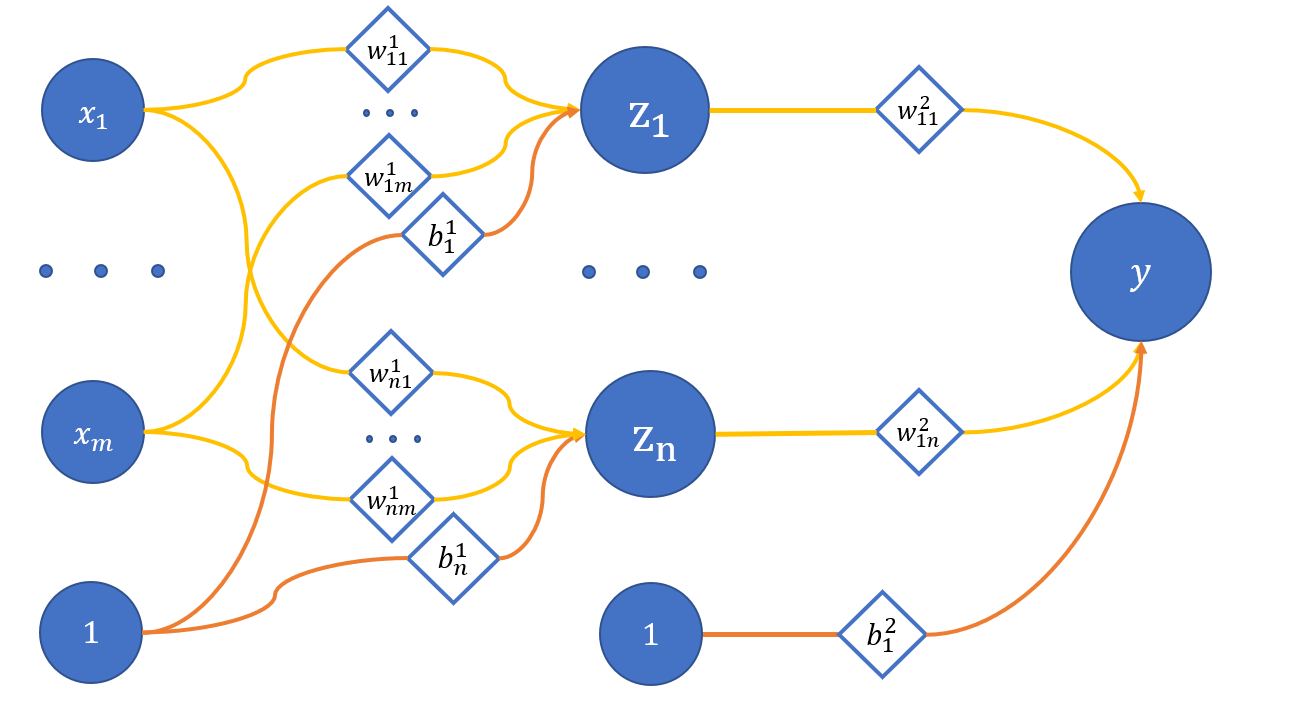
где
x_1 .. x_m - вход сети;
z_1 .. z_n - нейроны скрытого слоя;
y - выход сети;
w_{ij}^{(l)} - веса соответствующих связей между нейронами;
l - номер слоя, i - нейрон на l + 1 слое, j - нейрон на l слое;
b_i^{(l)} - смещения на соответствующих слоях.
Давайте в качестве примера рассмотрим сеть с тремя входами и тремя скрытыми нейронами (n = m = 3). Тогда вычисление значений скрытых нейронов:
Вычисление значения выходного нейрона:
Как решить оптимизационную задачу для такой модели? Возьмём всю ту же функцию ошибки:
Теперь необходимо понять, как же от неё вычисляется градиент. Для параметров выходного слоя проблем быть не должно, формулы тут похожи на те, что были для обычного нейрона:
И как было показано в предыдущем туториале:
Надо понимать, что z_j - известная для нас величина, так как мы получаем её при прямом проходе через сеть.
А как быть с параметрами скрытого слоя? Давайте распишем значение выходного слоя y подробнее:
Посмотрим вычисление градиента на примере определённого параметра, например, w_{11}^{(1)}:
Тогда:
В итоге обновление параметра w_{11}^{(1)} будет представлять из себя:
Аналогично можно вывести и для остальных параметров. Главное тут понять, что градиент параметров слоя l + 1 сети зависит от параметров слоя l (кроме смещений, которые не имеют связей с предыдущими слоями). Итак, пора реализовать всё это в коде.
Нейронная сеть: код¶
Начало почти ничем не отличается от туториала по нейрону, только на этот раз возьмём ещё и функцию ошибки из него же:
import numpy as np
import matplotlib.pyplot as plt
def show(x, y, pred=None, title=None):
plt.plot(x, y, linewidth=5, color="black", antialiased=True, label="True values")
if pred is not None:
plt.plot(x, pred, linewidth=2, color="orange", antialiased=True, label="Predicted values")
if title is not None:
plt.title(f'{title}')
plt.legend()
plt.show()
def showSubplots(x, y, *args, title=None):
fig = plt.figure(1, figsize=[10.4, 4.8])
for i, arg in enumerate(args):
i += 1
ax = fig.add_subplot(int("12{}".format(i)))
ax.plot(x, y, linewidth=5, color="black", antialiased=True, label="True values")
yp = arg["y"]
name = arg["name"]
color = arg["color"]
ax.plot(x, yp, linewidth=2, color=color, antialiased=True, label="{}".format(name))
ax.legend()
if title is not None:
fig.suptitle(f'{title}')
fig.show()
class Error:
@staticmethod
def value(true, pred):
return 0.5 * np.mean((true - pred) ** 2)
@staticmethod
def grad(true, pred):
c = 1 / np.prod(true.shape)
return -(true - pred) * c
X = np.linspace(-3, 3, 1000, dtype=np.float32).reshape(-1, 1)
def func(x):
return 2 * x + 3
f = np.vectorize(func)
Y = f(X)
Для этого туториала придётся немного поменять подход, потому что нам понадобятся два класса: класс слоя Linear и класс сети Net, причём класс слоя будет работать уже с тензорами.
Размерности тензоров
Так как в отличие от математического описания у нас появляется ось батча для данных, будет удобно работать с транспонированными относительно примера выше матрицами.
class Linear:
def __init__(self, insize, outsize, name=None):
self.w = np.random.randn(insize, outsize)
self.b = np.zeros((outsize, ))
self.inData = None
self.data = None
self.grad = None
self.name = name
def __call__(self, data):
return self.forward(data)
def forward(self, data):
self.inData = data
self.data = np.dot(data, self.w) + self.b
return self.data
def backward(self, grad):
delta = np.dot(grad, self.w.T)
self.grad = grad
return delta
def update(self, lr=0.1):
self.w -= np.dot(self.inData.T, self.grad) * lr
self.b -= np.dot(self.grad.T, np.ones(self.grad.shape[0], )) * lr
Методы похожи на те же у класса нейрона Neuron из прошлого туториала:
forward- прямой прогон данных через слой; нам необходимо здесь запоминать в атрибутах класса входящие данные, потому что они понадобятся при оптимизации параметров; операции теперь матричные;backward- прогон градиента через слой, учитывается влияние параметров текущего слоя на слои позади него;update- обновление параметров слоя по вышеприведённой формуле.
class Net:
def __init__(self):
self.layers = []
def __call__(self, data):
return self.predict(data)
def __getitem__(self, item):
return self.layers[item]
def append(self, layer):
self.layers.append(layer)
def backward(self, grad):
for layer in self.layers[::-1]:
grad = layer.backward(grad)
def update(self, lr):
for layer in self.layers:
layer.update(lr)
def predict(self, data):
for layer in self.layers:
data = layer.forward(data)
return data
def optimize(self, data, target, lr):
prediction = self(data)
# print("Simple net error {}".format(Error.value(target, prediction)))
grad = Error.grad(target, prediction)
self.backward(grad)
self.update(lr)
Для класса Net методы не нуждаются в объяснении, так как они аналогичны Linear, а метод optimize является копией такого же метода у Neuron.
Обучение сети¶
def trainNet(size, steps=1000, batchsize=10, learnRate=1e-2):
np.random.seed(4321)
net = Net()
net.append(Linear(insize=1, outsize=size, name="layer_1"))
net.append(Linear(insize=size, outsize=1, name="layer_2"))
predictedBT = net(X)
for i in range(steps):
idx = np.random.randint(0, 1000 - batchsize)
x = X[idx:idx + batchsize]
y = f(x).astype(np.float32)
net.optimize(x, y, learnRate)
predictedAT = net(X)
showSubplots(
X,
Y,
{
"y": predictedBT,
"name": "Net results before training",
"color": "orange"
},
{
"y": predictedAT,
"name": "Net results after training",
"color": "orange"
}
)
Попробуем обучить нашу сеть с двумя нейронами в скрытом слое на 100 шагах:
trainNet(2, steps=100, batchsize=1)
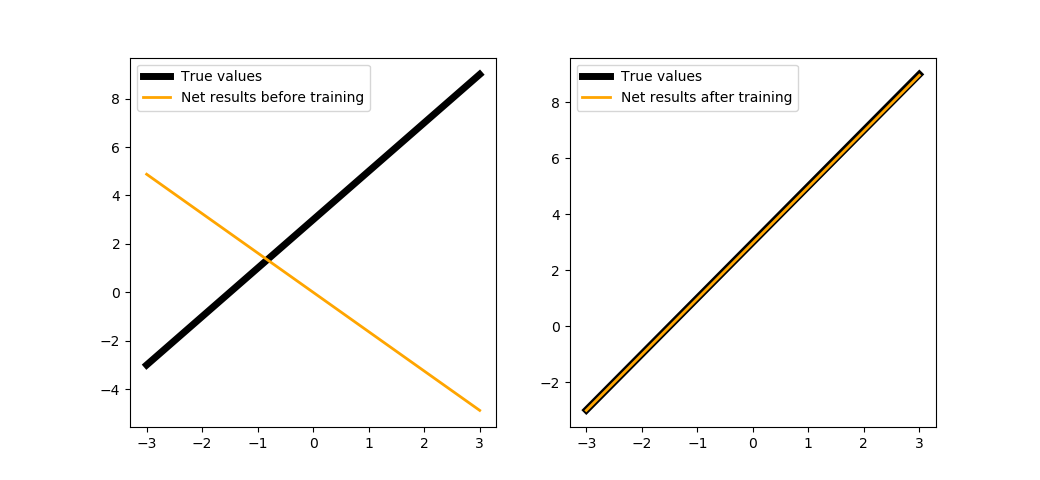
Как видно, с появлением скрытого слоя нам достаточно провести всего 100 шагов обучения, чтобы полностью восстановить функцию.
Реализация инструментами библиотеки¶
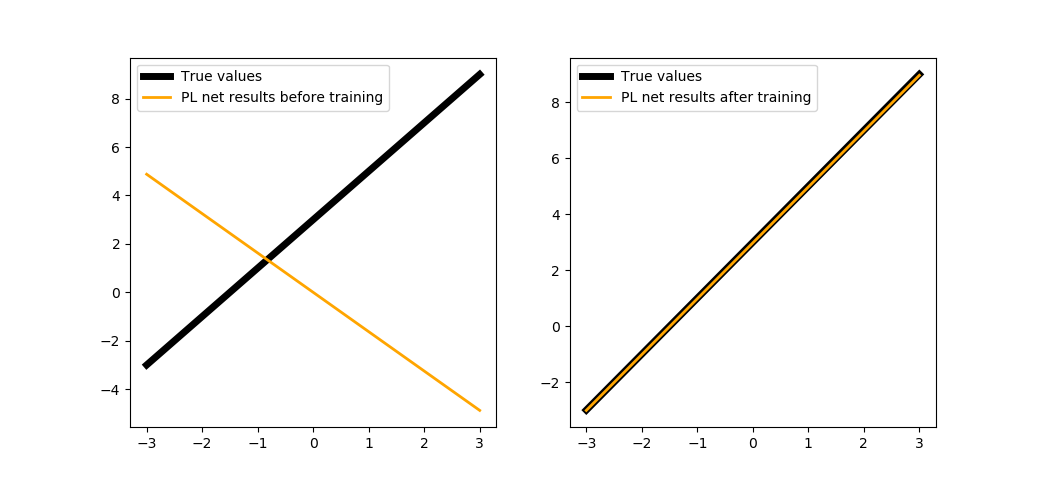
В этом туториале не будем проводить параллельное обучение, просто заведём отдельную функцию для обучения сети, написанной на PuzzleLib:
def trainNetPL(size, steps=1000, batchsize=10, learnRate=1e-2):
from PuzzleLib.Modules import Linear as LinearPL
from PuzzleLib.Containers import Sequential
from PuzzleLib.Optimizers import SGD
from PuzzleLib.Cost import MSE
from PuzzleLib.Handlers import Trainer
from PuzzleLib.Backend.gpuarray import to_gpu
np.random.seed(4321)
net = Sequential()
net.append(LinearPL(insize=1, outsize=size, name="layer_1", initscheme="gaussian"))
net.append(LinearPL(insize=size, outsize=1, name="layer_2", initscheme="gaussian"))
predictedBT = net(to_gpu(X)).get()
cost = MSE()
optimizer = SGD(learnRate)
optimizer.setupOn(net)
trainer = Trainer(net, cost, optimizer, batchsize=batchsize)
for i in range(steps):
idx = np.random.randint(0, 1000 - batchsize)
x = X[idx:idx + batchsize]
y = f(x).astype(np.float32)
trainer.trainFromHost(x, y, macroBatchSize=batchsize)
#,onMacroBatchFinish=lambda train: print("PL module error: %s" % train.cost.getMeanError()))
predictedAT = net(to_gpu(X)).get()
showSubplots(
X,
Y,
{
"y": predictedBT,
"name": "PL net results before training",
"color": "orange"
},
{
"y": predictedAT,
"name": "PL net results after training",
"color": "orange"
}
)
trainNetPL(2, steps=100, batchsize=1)
Усложнение функции¶
Может быть, усложним функцию, которую мы восстанавливаем?
def func(x):
from math import sin
return 2 * sin(x) + 5
f = np.vectorize(func)
Y = f(X)
trainNet(2, steps=100, batchsize=1)
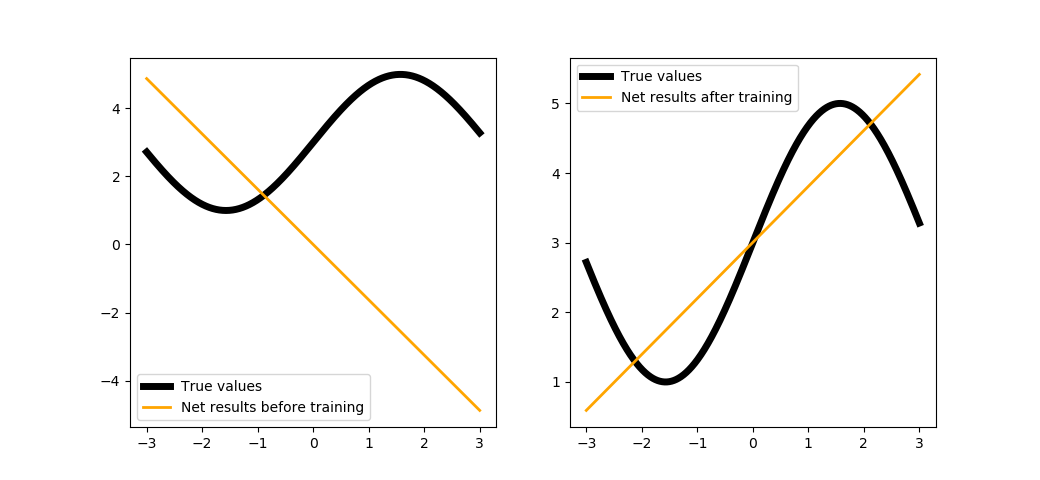
Можете попробовать обучить с большим количеством шагов, но всё равно ничего не выйдет. Объяснение простое: архитектура нашей сети сводится к линейной комбинации линейных функций (см. формулы выше), т.е. опять же является линейной функцией. Для того, чтобы решить эту проблему, в сеть вводится нелинейность - об этом в следующем туториале.