Конвертация в TensorRT engine¶
Введение¶
В этом туториале мы рассмотрим совместную работу библиотеки PuzzleLib с библиотекой TensorRT от NVIDIA.
TensorRT позволяет строить архитектуру нейронной сети более оптимальным образом и квантизировать входные данные для
сети, что дает нам либо то же, либо чуть более низкое качество работы сети и существенный прирост в скорости инференсв сети на GPU NVIDIA.
Установка TensorRT¶
Important
Технические требования:
- OS - Ubuntu 16.04/18.04 или Windows 10;
- Cuda 10.2 (можно по аналогии более ранние, начиная с 10.0+);
- CuDNN 7.6 (нужная версия cuDNN указана в названии соответствующего архива TensoRT)
- TensorRT 7.0 (можно по аналогии более ранние, начиная с 6.0+).
Important
Для Windows 10 понадобится Visual Studio 2017. Инсталлятор бесплатной версии можно скачать
здесь.
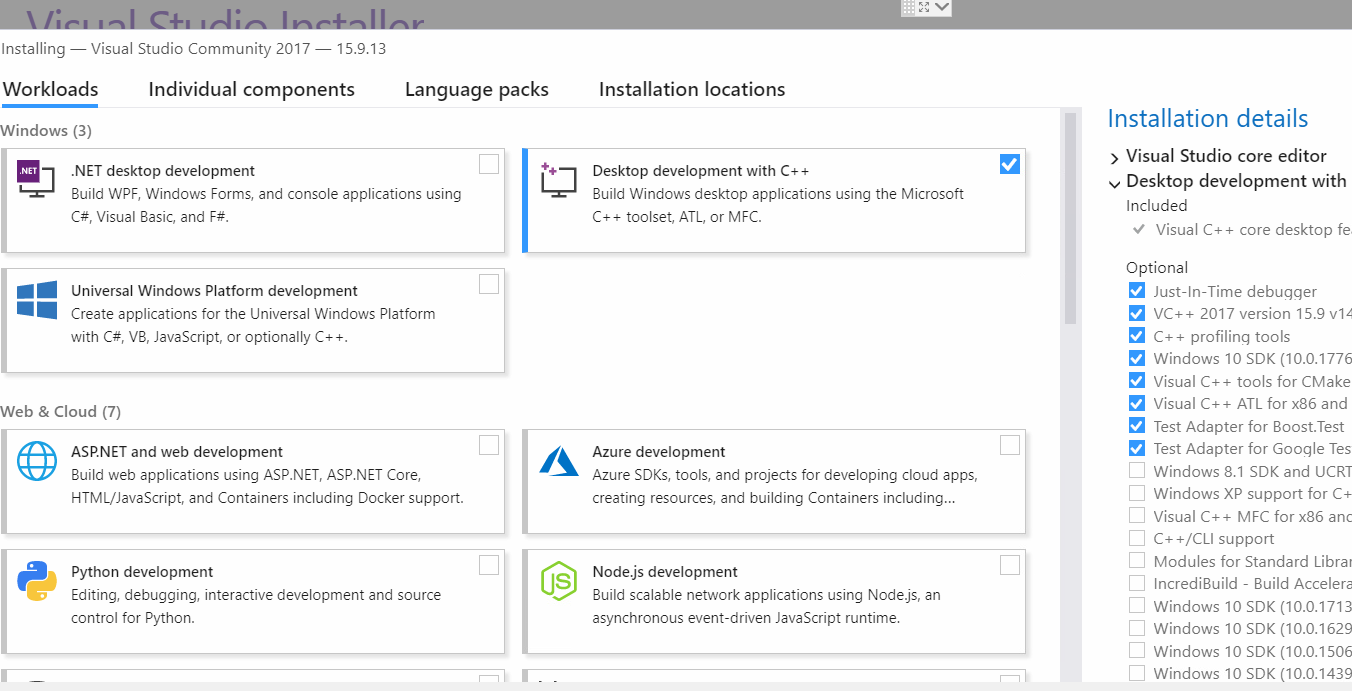
Следуем инструкциям инсталлятора. В момент выборка модулей сборки – выбираем только минимальный модуль для c++
(поставить галочку в соответствующем чек боксе).
{kind=link}
Последовательность действий:
- Проходим по ссылке с официального сайта NVIDIA с TensorRT 7.0. Логинимся или регистрируемся на сайте (это быстро).
- Прогружается страница с необходимой версией
TensorRT. Жмем галку в чек-боксе "I Agree To the Terms of the NVIDIA TensorRT License Agreement". - Жмем на ссылку "TensorRT 7.0" - выпадет список из вариантов установки
TensorRT.
При установке на Ubuntu 16.04 (18.04 по аналогии) к предыдущимм трем пунктам добавьте еще три:
U4. В TensorRT 7.0 for Linux => Tar File Install Packages For Linux x86 скачиваем TensorRT 7.0.0.11 for Ubuntu 16.04 and CUDA 10.2 tar package U5. Распаковываем в терминале архив и копируем часть содержимого:
tar xvz -f ~/Downloads/TensorRT-7.0.0.11.Ubuntu-16.04.4.x86_64-gnu.cuda-10.2.cudnn7.6.tar.gz
cd TensorRT-7.0.0.11
sudo cp lib/* /usr/lib/x86_64-linux-gnu/
sudo cp include/* /usr/include/
U6. Устанавливаем codepy и libboost (если они еще не установлены):
sudo pip3 install codepy
sudo apt-get install libboost-all-dev
При установке на Windows 10 добавьте к самым первым трем пунктам еще пять:
W4. В TensorRT 7.0 For Windows в Windows ZIP Package скачиваем Windows10 and CUDA 10.2 zip package
W5. Распаковываем архив. Все папки, кроме lib, переносим с заменой в папку: C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2 (по умолчанию, Cuda ставится именно туда).
W6. Все .dll файлы из папки lib переносим в папку C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\bin
W7. Все .lib файлы из папки lib кладем в папку C:\Program Files\NVIDIA GPU Computing Toolkit\CUDA\v10.2\lib\x64
W8. Устанавливаем codepy (если он еще не установлен):
pip3 install codepy
Сборка Driver¶
В библиотеке PuzzleLib есть папка Converter/TensorRT - это и есть мостик между PuzzleLib и TensorRT. Этот модуль
может конвертировать нейросетевые веса PuzzleLib в TensorRT engines, чем обеспечивает ускорение инференса сетей на NVIDIA GPU.
Запустите скрипт PuzzleLib/Converter/TensorRT/Source/Build.py. Он сгенерирует Driver.so в случае Ubuntu или Driver.pyd в случае Windows.
В этих бинарниках содержатся все низкоуровневые функции конвертации.
TensorRT float32¶
Нам понадобится скрипт PuzzleLib/Converter/TensorRT/Tests/ResNet50Test.py. Перед его запуском нужно скачать веса обученной модели ResNet-50-model.hdf и положить в папку PuzzleLib/Converter/TensorRT/TestData.
Скрипт начинается с импорта всех необходимых для его работы модулей и функций:
from PuzzleLib import Config
Config.globalEvalMode = True
from PuzzleLib.Backend import gpuarray
from PuzzleLib.Models.Nets.ResNet import loadResNet
from PuzzleLib.Converter.Examples.Common import loadResNetSample, loadLabels
from PuzzleLib.Converter.TensorRT.Tests.Common import scoreModels, benchModels
from PuzzleLib.Converter.TensorRT.BuildRTEngine import buildRTEngine, DataType
Подгружаем веса предобученной модели ResNet-50:
def main():
net = loadResNet(modelpath="../../TestData/ResNet-50-model.hdf", layers="50")
Подгружаем данные, которые будем пропускать через сеть. В данном случае - это одна фотография паука и список классов, соответствующих классам предобученной сети:
data = gpuarray.to_gpu(loadResNetSample(net, "../../TestData/tarantula.jpg"))
labels = loadLabels(synpath="../../TestData/synsets.txt", wordpath="../../TestData/synset_words.txt")
Самая важная функция - построение engine-файла, который заменит hdf-файл (и который, в дальнейшем, будет использоваться в качестве весов обученной модели для инференса сети). После отработки этой функции в папке PuzzleLib/Converter/TensorRT/TestData появится engine-файл по типу ResNet-50.float32.1-3-224-224.1-1000.GeForce_GTX_1080.engine.
Info
Название engine-файла содержит в себе следующую информацию:
ResNet-50- архитектура использованной сетиfloat32- формат данных, поданных сети на вход (может быть float32, float16 и int8)1-3-224-224- размерность батча данных, поданных сети на вход (размерность входного тензора сети, сконвертированной в engine)1-1000- размерность данных, полученных на выходе сети (размерность выходного тензора сети, сконвертированной в engine)GeForce_GTX_1080- видеокарточка, на которой были произведены рассчеты
engine = buildRTEngine(net, inshape=data.shape, savepath="../TestData", dtype=DataType.float32)
Сравниваем результаты работы сети с весами из hdf-файла и сети с весами из engine-файла формата float32 на 1 изображении:
scoreModels(net, engine, data, labels)
Должно получиться что-то вроде такого:
Net top-5 predictions:
#0 tarantula (prob=0.9944478)
#1 barn spider, Araneus cavaticus (prob=0.0049400954)
#2 doormat, welcome mat (prob=7.750382e-05)
#3 hair slide (prob=7.4750096e-05)
#4 earthstar (prob=7.231539e-05)
Engine top-5 predictions:
#0 tarantula (prob=0.9944478)
#1 barn spider, Araneus cavaticus (prob=0.004940091)
#2 doormat, welcome mat (prob=7.750382e-05)
#3 hair slide (prob=7.4750096e-05)
#4 earthstar (prob=7.231518e-05)
Как видим, результаты на одной и той же картинке совпадают (отличия в десятимиллионных долях не в счет).
В заключении, сравним время работы двух сетей на том же самом изображении:
benchModels(net, engine, data)
Должно получиться что-то вроде такого:
Net time: device=0.0171503003 host=0.0171508670
Engine time: device=0.0027132156 host=0.0027133632
TensorRT float32 отработал более чем в 6 раз быстрее. При этом, конечно, стоит помнить о том, что ResNet-50 хорошо
поддается оптимизации с помощью fusion (более сложные и нетипичные сети оптимизируются хуже и ускоряются чуть менее резво).
Float16 делается по аналогии - DataType.float32 нужно заменить на DataType.float16.
Но важно помнить, что данный формат не поддерживается на старых NVIDIA GPU (вылетит соответствующая ошибка).
TensorRT int8¶
Нам понадобится скрипт PuzzleLib/Converter/TensorRT/Tests/MnistLenetTest.py.
Скрипт начинается с импорта всех необходимых для его работы модулей и функций.
import numpy as np
from PuzzleLib.Backend import gpuarray
from PuzzleLib.Datasets import MnistLoader
from PuzzleLib.Containers import *
from PuzzleLib.Modules import *
from PuzzleLib.Handlers import *
from PuzzleLib.Optimizers import MomentumSGD
from PuzzleLib.Cost import CrossEntropy
from PuzzleLib.Converter.TensorRT.Tests.Common import benchModels
from PuzzleLib.Converter.TensorRT.BuildRTEngine import buildRTEngine, DataType
from PuzzleLib.Converter.TensorRT.DataCalibrator import DataCalibrator
Функция построения архитектуры сети LeNet:
def buildNet():
seq = Sequential(name="lenet-5-like")
seq.append(Conv2D(1, 16, 3))
seq.append(MaxPool2D())
seq.append(Activation(relu))
seq.append(Conv2D(16, 32, 4))
seq.append(MaxPool2D())
seq.append(Activation(relu))
seq.append(Flatten())
seq.append(Linear(32 * 5 * 5, 1024))
seq.append(Activation(relu))
seq.append(Linear(1024, 10))
return seq
В данном примере, у нас нет весов обученной модели, поэтому будем обучать модель сами с помощью функции обучения:
def trainNet(net, data, labels, epochs):
optimizer = MomentumSGD()
optimizer.setupOn(net, useGlobalState=True)
optimizer.learnRate = 0.1
optimizer.momRate = 0.9
cost = CrossEntropy(maxlabels=10)
trainer = Trainer(net, cost, optimizer)
validator = Validator(net, cost)
for i in range(epochs):
trainer.trainFromHost(
data[:60000], labels[:60000], macroBatchSize=60000,
onMacroBatchFinish=lambda train: print("Train error: %s" % train.cost.getMeanError())
)
print("Accuracy: %s" % (1.0 - validator.validateFromHost(data[60000:], labels[60000:], macroBatchSize=10000)))
optimizer.learnRate *= 0.9
Для сравнения результатов двух сетей (обычной и с весами из engine-файла), нам понадобится функция валидации:
def validate(net, data, labels, batchsize=1):
cost = CrossEntropy(maxlabels=10)
validator = Validator(net, cost, batchsize=batchsize)
return 1.0 - validator.validateFromHost(data[60000:], labels[60000:], macroBatchSize=10000)
Переходим к основной функции. Подгружаем данные для сети:
def main():
mnist = MnistLoader()
data, labels = mnist.load(path="../TestData/")
data, labels = data[:], labels[:]
print("Loaded mnist")
Фиксируем зерно генератора случайных чисел:
np.random.seed(1234)
Загружаем модель LeNet без весов.
net = buildNet()
Обучаем сеть:
trainNet(net, data, labels, 15)
Для получения TensorRT int8 engine нужно откалиброваться на тех данных, которые имеют смысл для исходной сети
(в данном случае - изображения с рукописным написанием цифр из датасета MNIST).
calibrator = DataCalibrator(data[:60000])
Переводим сеть в режим тестирования:
net.evalMode()
Строим engine-файл для TensorRT int8:
Info
Существенными отличиями TensorRT int8 от TensorRT float32 являются:
- формат данных
- наличие калибровки у TensorRT int8
- инференс int8 быстрее, но имеет более существенную погрешность в качестве (в некоторых задачах она может оказаться весьма ощутимой, для борьбы с этим нужно калиброваться на большом объеме данных)
engine = buildRTEngine(
net, inshape=data[:1].shape, savepath="../TestData", dtype=DataType.int8, calibrator=calibrator
)
Сравниваем результаты работы сети с весами из hdf-файла и сети с весами из engine-файла формата int8 на 1 изображении:
benchModels(net, engine, gpuarray.to_gpu(data[:1]))
TensorRT int8 быстрее в 4 с лишним раза:
Net time: device=0.0009059594 host=0.0009060884
Engine time: device=0.0002078026 host=0.0002083683
В заключении, сравним результаты работы сетей на всех данных:
print("Net accuracy: %s" % validate(net, data, labels))
print("Engine accuracy: %s" % validate(engine, data, labels, batchsize=1))
Должно получиться примерно следующее:
Net accuracy: 0.9933
Engine accuracy: 0.9931
Как видим, результаты ухудшились совсем незначительно.
Использование существующего engine-файла¶
Воспринимать engine-файл стоит так же, как и hdf-файл - веса сети. Единственным отличие в работе с ними заключается в подгрузке этого самого файла.
import os
from PuzzleLib.Converter.TensorRT.RTEngine import RTEngine, RTEngineType
engineFileName = "ResNet-50.float32.1-3-224-224.1-1000.GeForce_GTX_1080.engine"
enginePath = os.path.join("PuzzleLib", "Converter", "TensorRT", "TestData", engineName)
netEngine = RTEngine(enginepath=enginePath, enginetype=RTEngineType.puzzle)
В дальнейшем, используем netEngine как net (пример инференса):
import numpy as np
from pycuda import gpuarray
batchSize = 1
channelsCount = 3
imageSize = 224
batch = gpuarray.to_gpu(np.random.randn(batchSize, channelsCount, imageSize, imageSize).astype(np.float32))
forward = netEngine(batch)
result = forward.get()
Поздравляю, вы прошли туториал по TensorRT и научились ускорять инференс на NVIDIA GPU!