Restoring a linear function by a neural network¶
Neural network: theory¶
In the previous tutorial we discussed a simplified neuron (with one input and no activation) convenient for restoring a linear function. In this tutorial, we will complicate the architecture of our model and create a network of neurons with one hidden layer (the number of outputs will still equal one):
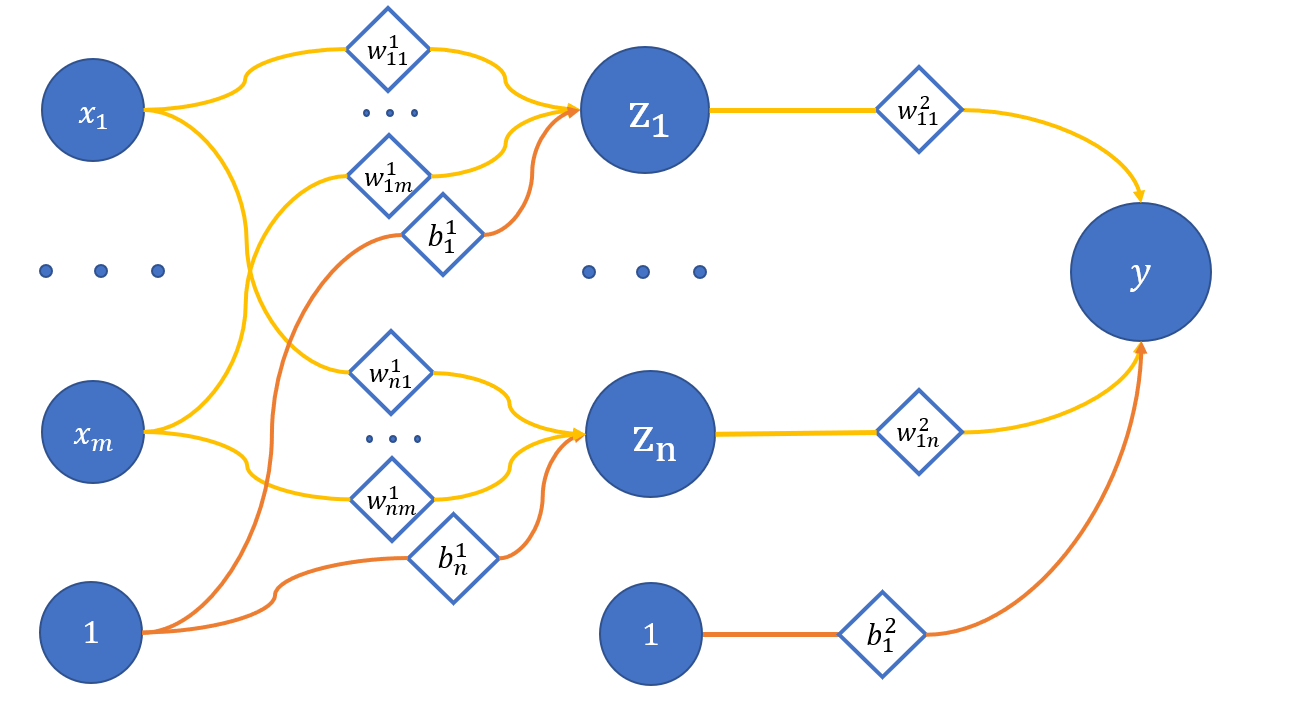
where
x_1 .. x_m - network input;
z_1 .. z_n - neurons of the hidden layer;
y - network output;
w_{ij}^{(l)} - weights of the corresponding connections between neurons;
l - layer number, i - neuron on l + 1 layer, j - neuron on the l layer;
b_i^{(l)} - biases on the corresponding layers.
Now we will look at a network with three inputs and three hidden neurons, e.g. n = m = 3. Сalculating the values of hidden neurons:
Calculating the output neuron value:
How do we solve the optimization problem for such model? Take the same loss function:
Now we need to understand how to calculate the gradient from it. There should be no problems with the parameters of the output layer. The formulas here are similar to those we had for a simple neuron:
As already shown in the previous tutorial:
We must understand that z_j is a known value, since we get it at the forward propagation.
What about the hidden layer parameters? We need to learn more about the value of the y output layer:
Check a gradient calculation of a certain parameter, e.g. w_{11}^{(1)}:
Then:
As a result, this would be updating the w_{11}^{(1)} parameter:
You can output the same for the other parameters just as well. It is crucial to understand that the gradient of the network's l layer parameters depends on the parameters of the l + 1 layer (but for biases that have no links to previous layers). Time to implement this in code.
Neural network: code¶
The beginning of the script is almost the same as in the tutorial on the neuron, but this time we also import the loss function from it:
import numpy as np
from Utils import show, showSubplots
from NeuronLinearTest import Error
X = np.linspace(-3, 3, 1000, dtype=np.float32).reshape(-1, 1)
def func(x):
return 2 * x + 3
f = np.vectorize(func)
Y = f(X)
We will need two classes for this tutorial, so you need to alter the approach a bit: the Linear layer class, and the network Net class, and the layer class will work with tensors.
The tensors dimensions
Since, in contrast to the mathematical description, we have a batch axis for the data, it will be convenient to work with matrices transposed in contrast to the example above.
class Linear:
def __init__(self, insize, outsize, name=None):
self.w = np.random.randn(insize, outsize)
self.b = np.zeros((outsize, ))
self.inData = None
self.data = None
self.grad = None
self.name = name
def __call__(self, data):
return self.forward(data)
def forward(self, data):
self.inData = data
self.data = np.dot(data, self.w) + self.b
return self.data
def backward(self, grad):
delta = np.dot(grad, self.w.T)
self.grad = grad
return delta
def update(self, lr=0.1):
self.w -= np.dot(self.inData.T, self.grad) * lr
self.b -= np.dot(self.grad.T, np.ones(self.grad.shape[0], )) * lr
The methods are similar to those of the neuron class Neuron from the previous tutorial:
forward- a forward propagation of data through the layer; we need to store the input data in class attributes here, because we will need it during parameters optimization; operations are now matrix;backward- runs the gradient through the layer, taking into account the effect of the current layer's parameters on the layers behind;update- updating the layer parameters using the aforementioned formula.
class Net:
def __init__(self):
self.layers = []
def __call__(self, data):
return self.predict(data)
def __getitem__(self, item):
return self.layers[item]
def append(self, layer):
self.layers.append(layer)
def backward(self, grad):
for layer in self.layers[::-1]:
grad = layer.backward(grad)
def update(self, lr):
for layer in self.layers:
layer.update(lr)
def predict(self, data):
for layer in self.layers:
data = layer.forward(data)
return data
def optimize(self, data, target, lr):
prediction = self(data)
print("Simple net error {}".format(Error.value(target, prediction)))
grad = Error.grad(target, prediction)
self.backward(grad)
self.update(lr)
Methods of the Net class require no explanation, since they are similar to Linear, and the optimize method is a copy of the same method for Neuron.
Network training¶
def trainNet(size, steps=1000, batchsize=10, learnRate=1e-2):
np.random.seed(4321)
net = Net()
net.append(Linear(insize=1, outsize=size, name="layer_1"))
net.append(Linear(insize=size, outsize=1, name="layer_2"))
predictedBT = net(X)
for i in range(epochs):
idx = np.random.randint(0, 1000 - batchsize)
x = X[idx:idx + batchsize]
y = f(x).astype(np.float32)
net.optimize(x, y, learnRate)
predictedAT = net(X)
showSubplots(
X,
Y,
{
"y": predictedBT,
"name": "Net results before training",
"color": "orange"
},
{
"y": predictedAT,
"name": "Net results after training",
"color": "orange"
}
)
We are going to try training our network with two neurons in a hidden layer in 100 steps:
trainNet(2, steps=100, batchsize=1)
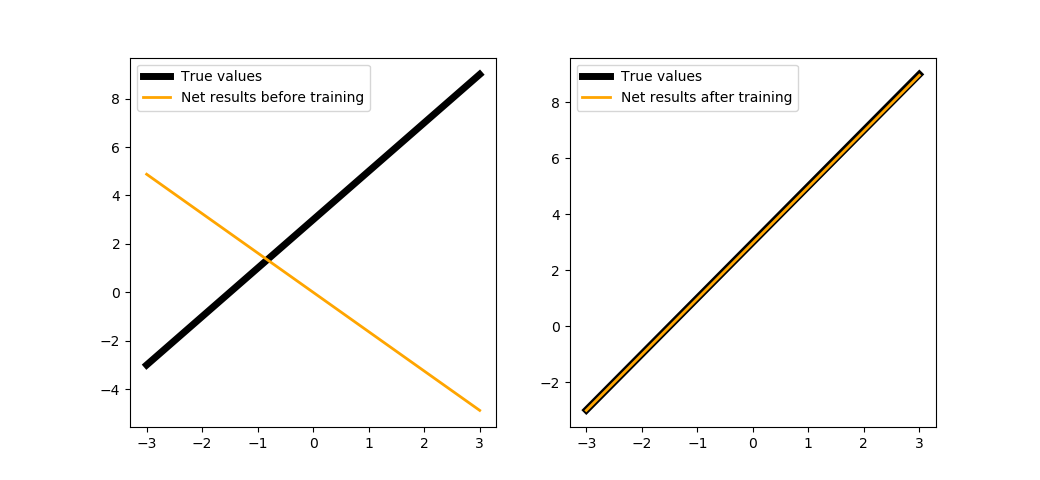
As you might see, we only need to spend 100 steps of training to fully restore the function since we have the hidden layer.
Implementing the library tools¶
In this tutorial, we will not conduct parallel training, just create a separate function for training a network written in PuzzleLib:
def trainNetPL(size, steps=1000, batchsize=10, learnRate=1e-2):
from PuzzleLib.Modules import Linear as LinearPL
from PuzzleLib.Containers import Sequential
from PuzzleLib.Optimizers import SGD
from PuzzleLib.Cost import MSE
from PuzzleLib.Handlers import Trainer
from PuzzleLib.Backend.gpuarray import to_gpu
np.random.seed(4321)
net = Sequential()
net.append(LinearPL(insize=1, outsize=size, name="layer_1", initscheme="gaussian"))
net.append(LinearPL(insize=size, outsize=1, name="layer_2", initscheme="gaussian"))
predictedBT = net(to_gpu(X)).get()
cost = MSE()
optimizer = SGD(learnRate)
optimizer.setupOn(net)
trainer = Trainer(net, cost, optimizer, batchsize=batchsize)
for i in range(steps):
idx = np.random.randint(0, 1000 - batchsize)
x = X[idx:idx + batchsize]
y = f(x).astype(np.float32)
trainer.trainFromHost(x, y, macroBatchSize=batchsize,
onMacroBatchFinish=lambda train: print("PL module error: %s" % train.cost.getMeanError()))
predictedAT = net(to_gpu(X)).get()
showSubplots(
X,
Y,
{
"y": predictedBT,
"name": "PL net results before training",
"color": "orange"
},
{
"y": predictedAT,
"name": "PL net results after training",
"color": "orange"
}
)
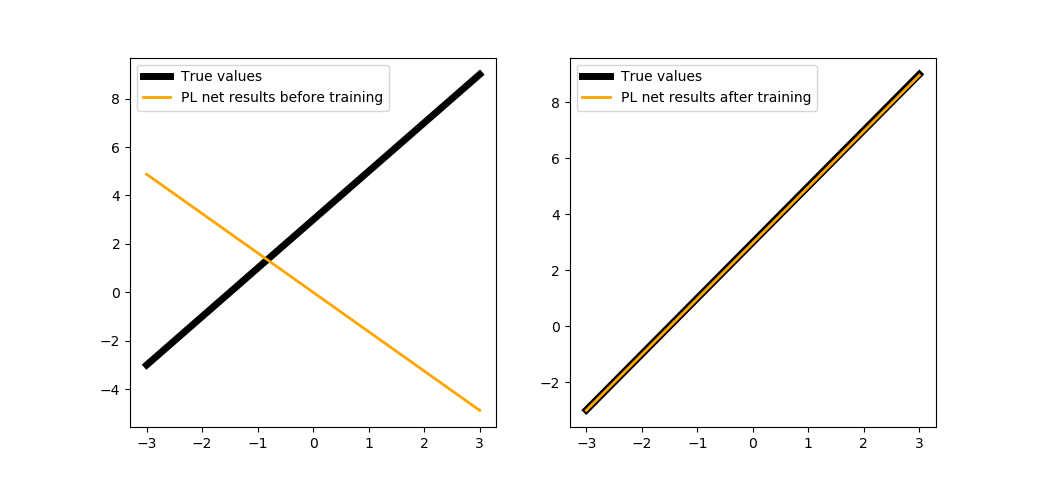
Complicating the function¶
Why not complicate the function we are restoring?
def func(x):
from math import sin
return 2 * sin(x) + 5
f = np.vectorize(func)
Y = f(X)
trainNet(2, steps=100, batchsize=1)
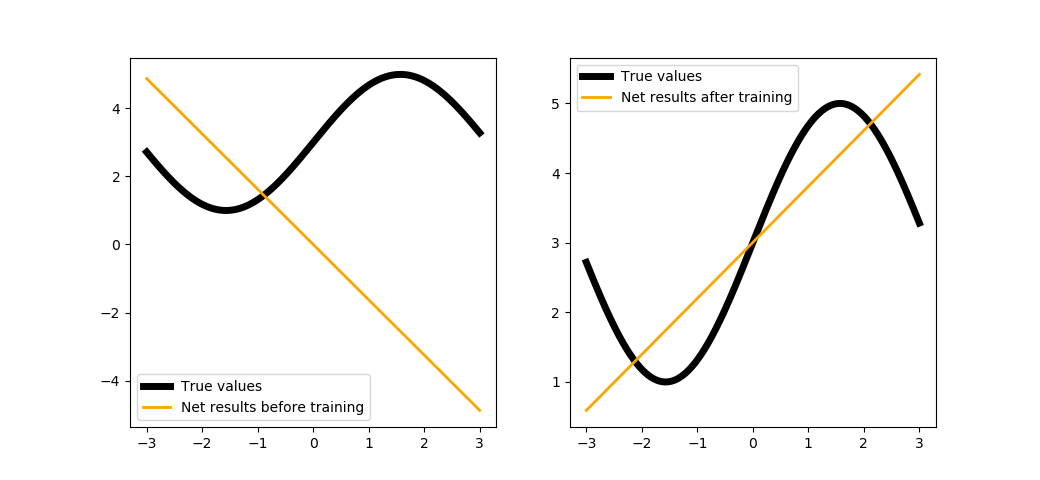
You could try training with a larger number of steps, but it would not work anyway. The explanation is simple: the architecture of our network is reduced to a linear combination of linear functions (see the formulas above), i.e. it is merely a linear function. In order to solve this problem, we introduce non-linearity into the network - see the next tutorial for more information on that.