MomentumSGD¶
Description¶
This module implements the momentum stochastic gradient descent - MomentumSGD.
The regular stochastic gradient descent has a number of drawbacks, one of which is the difficulty in working with the “ravines” of the error function — those parts of the surface with a noticeable spread in the change rate of the function depending on the direction (see Figure 1.a) In such cases, the SGD algorithm spends most of its energy on oscillations along the slopes of the "ravine", which is why the progress to a minimum is slowed down.
The use of an additional momentum in this algorithm allows you to muffle the vibrations and accelerate the progress in the relevant direction (see Figure 1.b).
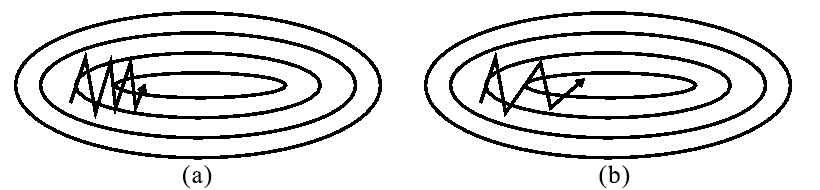
Analytically, this is expressed by adding the decay rate γ, which is responsible for how much of the gradient from the previous step to take into account at the current step (here, we omit some notation that was present in the formulas for SGD for simplicity):
\begin{equation} g_t = \gamma{g_{t-1}} + (1 - \gamma)\eta\nabla_\theta J(\theta_t) \end{equation} \begin{equation} \theta_{t+1} = \theta_t - g_t \end{equation}
where
\theta_{t+1} - updated set of parameters for the next optimization step;
\theta_t - set of parameters at the current step;
\gamma - exponential decay rate (usually about 0.9);
\eta - learning rate (in some versions of the formula, it includes the (1 - \gamma) factor);
\nabla_{\theta}J(\theta_t) - gradient of the error function.
Initializing¶
def __init__(self, learnRate=1e-3, momRate=0.9, nodeinfo=None):
Parameters
| Parameter | Allowed types | Description | Default |
|---|---|---|---|
| learnRate | float | Learning rate | 1e-3 |
| momRate | float | Exponential decay rate | 0.9 |
| nodeinfo | NodeInfo | Object containing information about the computational node | None |
Explanations
-
Examples¶
Necessary imports:
import numpy as np
from PuzzleLib.Optimizers import MomentumSGD
from PuzzleLib.Backend import gpuarray
Info
gpuarray is required to properly place the tensor in the GPU.
is required to properly place the tensor in the GPU.
data = gpuarray.to_gpu(np.random.randn(16, 128).astype(np.float32))
target = gpuarray.to_gpu(np.random.randn(16, 1).astype(np.float32))
Declaring the optimizer:
optimizer = MomentumSGD(learnRate=0.01, momRate=0.85)
Suppose there is already some net network defined, for example, through Graph, then in order to install the optimizer on the network, we need the following:
optimizer.setupOn(net, useGlobalState=True)
Info
You can read more about optimizer methods and their parameters in the description of the Optimizer parent class
Moreover, let there be some loss error function, inherited from Cost, calculating its gradient as well. Then we get the implementation of the optimization process:
for i in range(100):
... predictions = net(data)
... error, grad = loss(predictions, target)
... optimizer.zeroGradParams()
... net.backward(grad)
... optimizer.update()
... if (i + 1) % 5 == 0:
... print("Iteration #%d error: %s" % (i + 1, error))