BatchNormND¶
Описание¶
Общая информация¶
Этот модуль выполняет операцию N-мерной батч-нормализации. Выбор размерности операции зависит от размерности входных данных.
Слой батч-нормализации призван, в первую очередь, решать проблему ковариационного сдвига. Понять ковариационный сдвиг проще всего на примере: допустим, есть сеть, которая должна распознавать изображения кошек. В обучающей выборке присутствуют изображения только чёрных кошек, так что, когда мы попытаемся во время тестов прогнать картинки кошек других цветов, нежели чёрный, качество предсказания модели будет заметно хуже, чем на сете из чёрных кошек. Другими словами, ковариационный сдвиг — это ситуация, когда распределения значений признаков в обучающей и тестовой выборке имеют разные параметры (математическое ожидание, дисперсия и т.д.).
Когда мы говорим о ковариационном сдвиге в рамках глубокого обучения, мы в большей мере имеем в виду ситуацию разного распределения признаков не на входе сети, как в примере выше, а в слоях внутри модели - внутренний ковариационный сдвиг. Нейронная сеть меняет свои веса с каждым пройденным мини-батчем (если мы применяем соответствующий оптимизационный механизм, естественно), и так как выходы текущего слоя являются входными признаками для следующего, то каждый слой в сети попадает в ситуацию, когда распределение входных признаков меняется каждый шаг, т.е. каждый пройденный мини-батч.
Базовая идея батч-нормализации - ограничить внутренний ковариационный сдвиг путём нормализации выхода каждого слоя, преобразуя его в распределениу с нулевым математическим ожиданием и единичной дисперсией.
Из рисунка 1 видно, что батч-нормализация получает среднее и дисперсию по батчу.
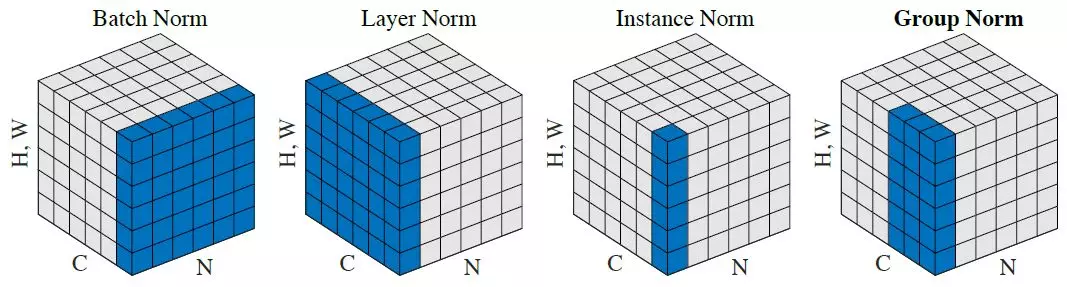
Рассмотрим случай батч-нормализации двумерных карт. Тогда тензор данных имеет размерность (N, C, H, W), где N - размер батча, C - количество карт (каналов), H - высота карты, W - ширина карты. Условимся насчёт индексов: t - номер элемента батча, i - номер карты, m - номер элемента карты признаков по высоте, n - номер элемента карты признаков по ширине. Тогда для каждой отдельно взятой i-ой карты признаков:
где
\mu_i - математическое ожидание распределения признаков в батче для i-ой карты признаков;
\sigma_i^2 - дисперсия распределения признаков в батче для i-ой карты признаков;
x_{timn} - элемент карты признаков;
\hat{x}_{timn} - нормализованный элемент карты признаков;
\epsilon - стабилизирующая константа, предотвращающая деление на ноль;
\gamma - аффинный параметр масштаба;
\beta - аффинный параметр сдвига.
Для параметров \mu_i и \sigma_i^2 слои батч-нормализации запоминают среднее значение по всей выборке за время обучения. Во время инференса эти параметры замораживаются.
На практике ограничение в лице нулевого мат ожидания и единичной дисперсии может сильно ограничить предсказательную способность сети, поэтому добавляются ещё два обучаемых аффинных параметра: масштаб и сдвиг, чтобы алгоритм мог подстроить под себя значения среднего и дисперсии.
Дополнительные источники¶
Подробнее о батч-нормализации можно почитать в следующих источниках:
Инициализация¶
def __init__(self, nd, maps, epsilon=1e-5, initFactor=1.0, minFactor=0.1, sscale=0.01, affine=True, name=None, empty=False, inplace=False):
Параметры
| Параметр | Возможные типы | Описание | По умолчанию |
|---|---|---|---|
| nd | int | Размерность операции | - |
| size | int | Количество входных признаков | - |
| epsilon | float | Стабилизирующая константа | 1e-5 |
| initFactor | float | Начальное значение коэффициента сохранения в скользящем среднем | 1.0 |
| minFactor | float | Минимальное значение коэффициента сохранения в скользящем среднем | 0.1 |
| sscale | float | Дисперсия гауссовского распределения для масштабов scale batch нормализации |
0.01 |
| affine | bool | Если True, слой будет иметь обучаемые аффинные параметры scale и bias |
True |
| name | str | Имя слоя | None |
| empty | bool | Если True, то тензоры параметров модуля не инициализируются | False |
| inplace | bool | Если True, то выходной тензор будет записан в памяти на место входного | False |
Пояснения
См. классы потомки.