InstanceNorm2D¶
Description¶
This module implements the operation of two-dimensional instance normalization.
Instance normalization is used to train generative neural networks, as normalization by batch has a negative effect on their learning speed and the quality of the result. In batch normalization, statistics are computed over several images, which is why information about each individual image is lost.
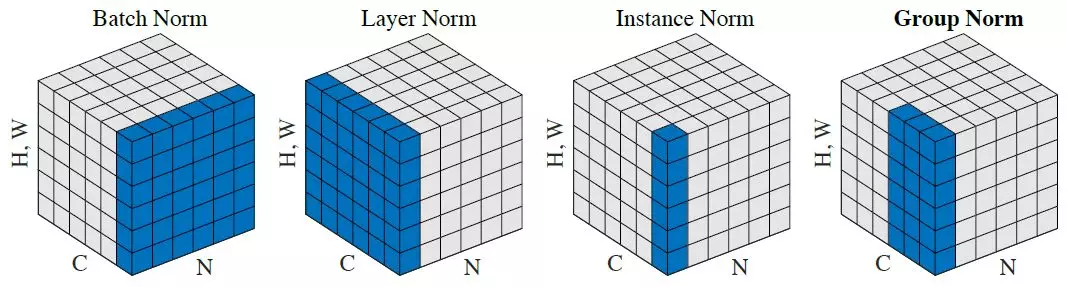
The data tensor at the input to the module has the dimension (N, C, H, W), where N - size of the batch, C - number of maps (channels), H - height of the map, W - width of the map. Let us agree on the indexes: t - number of the batch element, i - number of the map, m - number of the feature map element in height, n - number of the feature map element in width. Then, for each separately taken combination of the t-th element of the batch and the i-th feature map:
where
\mu_{ti} - mathematical expectation of the attributes distribution for a single given combination of the t-th batch element and the i-th feature map;
\sigma_{ti}^2 - variance of the feature distribution for a single given combination of the t-th batch element and the i-th feature map;
x_{timn} - feature map element;
\hat{x}_{timn} - normalized feature map element;
\epsilon - stabilizing constant that prevents division by zero;
\gamma - affine scale parameter;
\beta - affine bias parameter.
In practice, the restriction represented by zero mathematical expectation and unit variance can greatly limit the predictive ability of the network, therefore two more trained affine parameters are added: scale and bias, so that the algorithm can adjust the average and variance values for itself.
Additional sources¶
Initializing¶
def __init__(self, numOfMaps, epsilon=1e-5, affine=True, name=None):
Parameters
| Parent | Allowed types | Description | Default |
|---|---|---|---|
| numOfMaps | int | Number of maps | - |
| epsilon | float | Small bias coefficient | 1e-5 |
| affine | bool | Use of affine transformations | True |
| name | str | Layer name | None |
Explanations
affine - flag that controls whether scale and bias parameters of the batch normalization layer will be trained or fixed (1 and 0, respectively), so that the layer will perform only the operation of normalization by average and variance.
Examples¶
Necessary imports
import numpy as np
from PuzzleLib.Backend import gpuarray
from PuzzleLib.Modules import InstanceNorm2D
Info
gpuarray is required to properly place the tensor in the GPU
batchsize, maps, h, w = 5, 3, 4, 4
data = gpuarray.to_gpu(np.random.randn(batchsize, maps, h, w).astype(np.float32))
instNorm2d = InstanceNorm2D(numOfMaps=maps)
instNorm2d(data)